Decision Trees
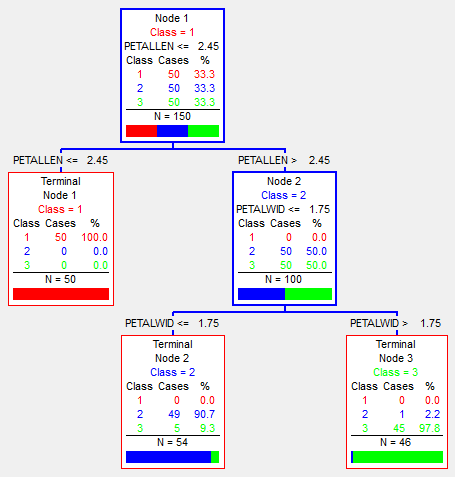
Decision trees idea is to build a set of rules in hierarchical form, that will allow to predict the value of a target variable. Rules are usually in form of "if-then-else" statements and organized in the form of a binary tree.
Basic reading:
Hardcore reading:
Original book, which describes methodology: Classification And Regression Trees. Leo Breiman, Jerome Friedman, Charles Stone, Richard Olshen.
Stochastic Gradient Boosting of Decision Trees
This method of building predictive model is based on constructing a set of small regression decision trees, that are fitted (learned) sequentially, where each next iteration learns from error of previous iterations.
Basic reading:
Hardcore reading:
Original paper, which describes methodology: Jerome Friedman. Stochastic Gradient Boosting.
Random Forests
The idea behind Random Forests, is that you are building strong classifiers on independently sampled data subsets, while using random selection of features to split each node. The generalization error for forests like this converges to a limit as the number of trees in the forest becomes large.
Basic reading:
Hardcore reading:
Original paper, which describes methodology: Leo Breiman, Random Forests.
As a conclusion, I would say that all three methods have their own advantages and disadvantages and it's worth learning how and when to use each on of them.